In the past I had the opportunity to use some of the NLP capabilities available in Amazon Comprehend. This time I wanted to give it a shoot at Google Cloud Platform and try some of the features offered in Google Natural Language. As I wanted to validate feasibility, I wanted to use only serverless products. I ended up using Cloud Storage, Cloud functions, Firestore and AppEngine. All the code is available at estebanf/serveless-nlp (github.com) and here are my notes of the journey, the comparison with previous AWS experience and my overall takeaways.
First step was to create my Storage bucket. Nothing too fancy here, just a private bucket in my project
My goal is to build a dataset with the extracted information, so Firestore was my next stop. I set it up to be Native mode and created my collection.
Next was to create my function. In this case I wanted it to be triggered by the creation of a document in my bucket.
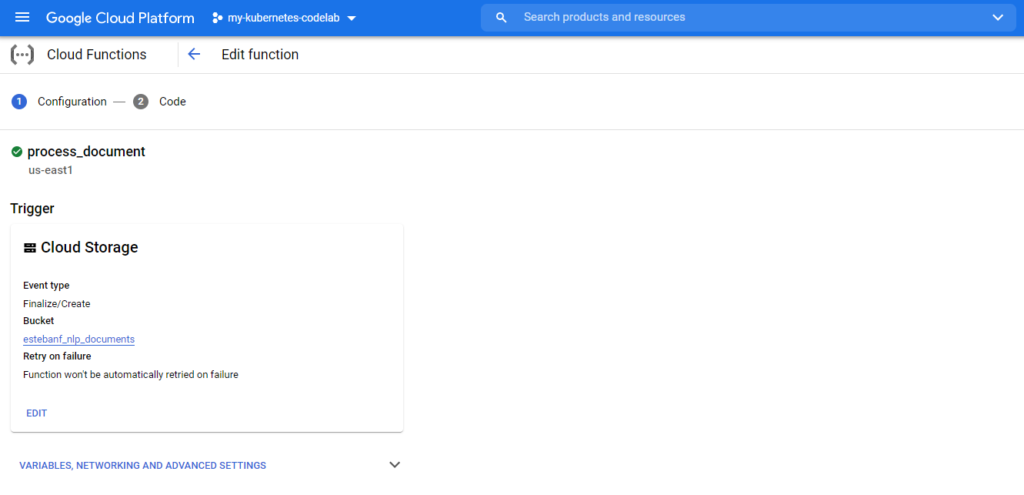
The code is quite simple:
- Get details of the created document.
- Call analyzeEntities from the language API. Some data manipulation with lodash to make the results more manageable.
- Call classifyText from the language API.
- Add the entry to the firestore collection.
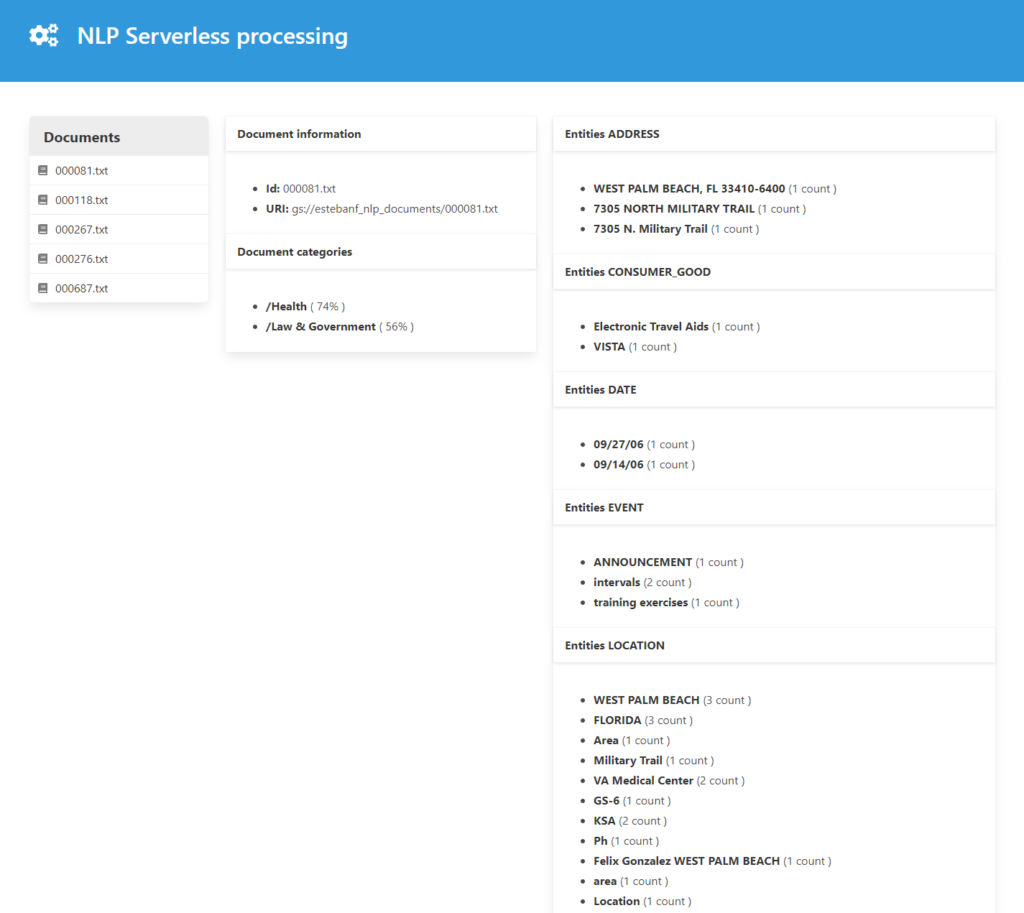
Finally, I needed a UI to visualize the results. A simple webapp with ExpressJS on the server and Vue.js in the frontend, all deployed to AppEngine. Here is a screenshot.
Comparing to AWS:
- The language API will take a cloud storage URI as input. That is great and much better of what AWS Comprehend does. AWS required me to pass the text and I would face at 5000 bytes limit.
- Google scores a point for offering a classifyText method without requiring preliminary work. Not similar straight forward capability is available in AWS.
- The language API need the document to be PLAIN_TEXT. It is a bummer but fair enough. A more realistic example would need a preliminary phase to process the document with a library like Apache Tika to extract the text.
- GCP supports WORK_OF_ART which is not present in AWS Comprehend. AWS would extract QUANTITY while GCP gives NUMBER and PRICE. AWS has COMMERCIAL_ITEM while GCP calls it CONSUMER_GOOD
- Creating a cloud function in GCP was smoother mostly because I could configure it to bring the code from a source code repository. Both platforms give you the option code directly in the configuration screen or upload the code to a bucket. I cannot see that being useful beyond doing something quick.
- AWS Lambda wins in terms of testability and deployment. They give you a test button right there and you can configure several cases. Deployment is also way faster. In GCP every time I had to deploy it would text my patience.
Takeaways
Most of all, results were “Meh”. But that is a problem that generally exists in this area. There is too much noise and to make the extracted useful some contextual knowledge is required.
But the whole exercise took over a couple of hours which is impressive. At the end I have a solution that should withstand significant loads at a reasonable price with minimum effort. It is a confirmation that beyond the usual use cases of serverless computing, we product leaders can leverage these options to validate concepts and deliver an outstanding time to market.